傳統的「搜尋/取代」,功能非常簡單,
只要「搜尋」到某個東西,
不管三七二十一就把它直接「取代」了。
我們昨天完成的「詞語代換」,功能稍微進階了一點,
它會參考「原文」做為線索,
只有在「原文」出現的前提下,才會到譯文中「搜尋」某些詞語,
然後再用我們想要的譯文加以「取代」。
因為在進行「搜尋/取代」時,多了其他「線索」做為參考,
(以這裡來說,相應的「原文」就是線索)
因此可達到更精準的詞語替換效果。
不過,這樣的做法還不夠完美。
舉例來說,我們可以用「Manifest V3 migration checklist」
這個頁面做為例子。
這個頁面標題的機器翻譯為「清單 V3 遷移清單」。
我們可以看到,
原文中的 Manifest 和 checklist,全都被翻譯成「清單」。
實際上,
我們希望 Manifest 這個字能保留原文,
checklist 則可替換成「檢查項目表」
因此,我們可能會在 saved_terms 保存兩組替換項目:
saved_terms = {
...
'Manifest': {mt_text:'清單', tt_text:'Manifest', ...},
'checklist': {mt_text:'清單', tt_text:'檢查項目表', ...},
...
}
之後如果引用這兩組記錄來進行詞語代換,
假設先執行 Manifest 這個項目,
原本的「清單 V3 遷移清單」就會被替換成「Manifest V3 遷移 Manifest」,
後來想要再根據 checklist 這個項目進行替換時,
內文中已經沒有「清單」二字,
因此就不會再進行任何替換動作了。
最後的結果就是「Manifest V3 遷移 Manifest」,
這顯然是個有問題的替換結果。
雖然原本的「清單 V3 遷移清單」很有問題,
但替換之後的結果也沒高明多少。
如果先替換 checklist 再替換 Manifest,
結果更加奇怪,完全不是可接受的結果。
這其中最主要的問題,就在於我們並不知道,
原來的譯文「清單 V3 遷移清單」中,
第一個「清單」對應的是 Manifest,
第二個「清單」則是對應 checklist。
如果在判斷時,能多一點有用的線索,
一定有助於做出更好的替換。
另一方面,如果確實取得了更多的線索,
究竟該如何衡量不同線索對於正確判斷的影響,
這也是很重要的另一個問題。
實際上,如果線索夠多、而且確實都是有用的線索,
幾乎就可以做出非常精準的判斷。
這個部分也是機器學習、人工智慧可以派上用場之處。
不過,我們今天的主題,
則是想辦法找出更多有用的線索。
其實要找出更多線索,同樣也可運用機器學習的成果。
比如我們今天所要介紹的「語法分析」功能,
就是機器學習快速發展下、一個十分好用的成果。
我們可以把句子交給「語法分析」API 進行解析,
結果就會送回每個詞語的詞性、在句中所扮演的角色、每個詞的原型等資訊。
有了詞語的詞性,
當然就可以進行更精準的替換。
有了單詞的原型,
我們就不必針對單詞的各種不同形式,
分別定義重複的代換規則,
面對沒見過的變形詞語,
只要其原型做過定義,
代換規則依然可以發揮作用。
詞語在句中所扮演的角色,
不但可以協助判斷,
甚至還能與其他詞語構成片語,
進行更高級的代換功能。
由此可見,
「語法分析」對於翻譯修正工作來說,
實在是非常有用的功能。
我們這兩天就來介紹如何導入「語法分析」功能吧。
這裡打算使用的是 Google 的 Cloud Natural Language API,
其中有一個叫做 Analyzing Syntax 【分析語法】的功能。
為了使用這個語法分析的功能,
我一開始的想法是希望先嘗試看看,
能不能直接利用【背景服務】的 fetch() 函式,
來取得語法分析的結果。
但後來我發現,
事情並沒有想像中那麼簡單。
最後迫不得已,只好改用 Python 的做法。
一試之下,居然就成功了。
所以,我們終於要被迫改用 Python 了哈哈哈。。。
首先,請各位把 Python 安裝起來吧。
通常我會直接安裝 Anaconda,其中包含了許多好用的工具,
建議您也可以試試看。
具體的安裝步驟,這裡就不展開了。
安裝好之後,
我們準備啟動一個新的 Python 專案,
姑且就叫它 bt_server 好了。
我們先找個合適的位置,建立一個叫做 bt_server 的目錄。
然後目錄上點擊滑鼠右鍵,選擇【Git Bash Here】
(這是之前安裝 Git 就會有的右鍵功能選項)
進入指令行,進行一些準備工作。
一開始,我們一樣先用 git init 開始記錄程式碼歷程,
並到 Github 建立一個遠端程式碼儲存庫,
再與本機這邊聯繫起來:
git init
git remote add origin https://github.com/betterTrans/bt_server.git
接下來我們建立一個虛擬環境,然後進入虛擬環境中:
conda create --name bt python=3
source activate bt
然後我們再把 flask 和 google-cloud-language 安裝起來:
pip install flask google-cloud-language
這樣我們就可以開始寫 Python 程式了。
同樣的,我們可以在 bt_server 這個目錄按下滑鼠右鍵,
選擇【以 Code 開啟】,就可以用 VScode 開啟這個目錄了。
我們在 bt_server 目錄下,
建立第一個 Python 檔案 bt_server.py,
然後寫下一段簡短的 flask 程式碼如下:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "<h1>「更好的翻譯」隆重登場!</h1>"
if __name__ == "__main__":
app.run(port=80, debug=True)
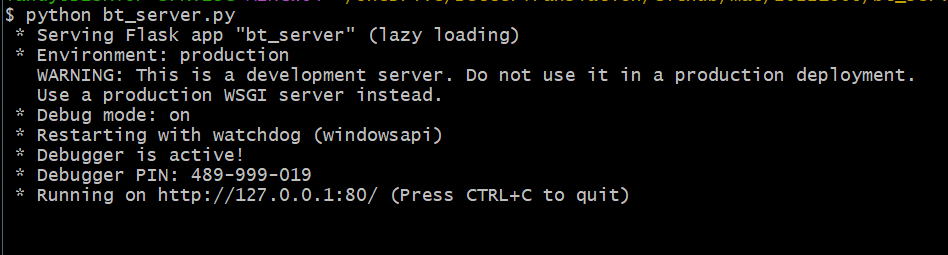
保存好檔案之後,回到 Bash 指令行界面中,輸入以下指令:
python bt_server.py
這樣就可以看到程式已經執行起來了!
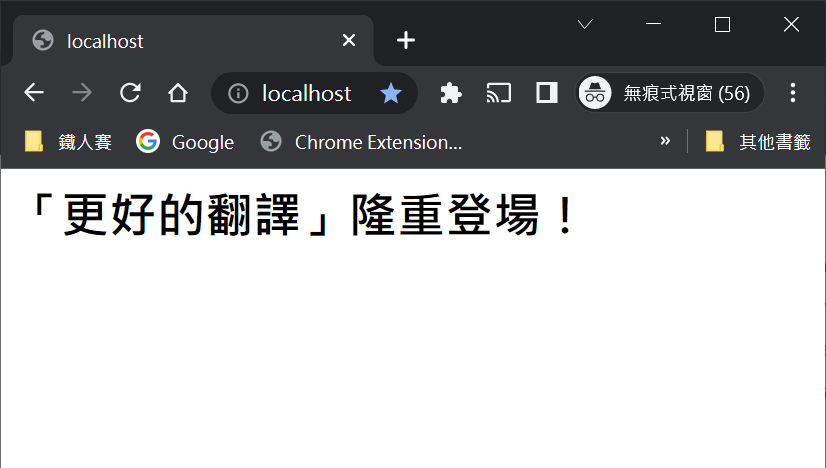
接著只要打開瀏覽器,在網址列輸入:
http://localhost/
就可以看到我們的 bt_server 所提供的頁面了。
這就是一個最簡單的 flask 應用程式。
程式碼裡的下面這三行,定義了網址根目錄所要顯示的內容:
@app.route("/")
def hello():
return "<h1>「更好的翻譯」隆重登場!</h1>"
接下來,我們就要利用這個 flask 程式,
提供語法分析的服務。
嚴格來說,flask 只是做為中間的代理服務,
它可以接收我們請求,
然後代替我們向外部請求 Google 進行語法分析,
接著取得結果之後,再將結果送回給我們。
要使用 Google 的語法分析 API,必須先完成下面這幾個動作:
export GOOGLE_APPLICATION_CREDENTIALS=/c/json檔案的完整路徑/service-account.json
也可以把這行設定寫入到 ~/.bashrc 內,將來進入 bash 指令行界面時就會自動執行了
這樣就算是把 Google API 所需的憑證設定好了。
接著再來看看 server 的 Python 程式碼。
為了讓程式可順利接收我們的請求,並向 google 發出請求,
我們的程式一開始就要匯入相應的函式庫如下:
from flask import Flask, request, abort
from google.cloud import language_v1 as language
import json
然後再定義一個 API 路徑,接受語法分析的請求:
@app.route('/api/syntax', methods=['POST'])
def api_syntax():
...
api_syntax() 這個函式,一開始會先從我們的請求中,
取出要進行分析的句子:
data = json.loads(request.values.get("data"))
sentence = data["sentence"]
接著就可以送去進行語法分析了:
client = language.LanguageServiceClient()
document = {
"content": sentence,
"type_": language.Document.Type.PLAIN_TEXT,
"language": "en"
}
analyze_result = client.analyze_syntax(
request = {
'document': document,
'encoding_type': language.EncodingType.UTF8
}
)
所取得的這個分析結果 analyze_result,
是一個相當複雜的物件。
我們只會從中取出部分的資訊:
sentences = [
{
"text": {
"content": sent.text.content,
"beginOffset": sent.text.begin_offset
}
}
for sent in analyze_result.sentences
]
tokens = [
{
"text": {
"content": token.text.content,
"beginOffset": token.text.begin_offset
},
"partOfSpeech": {
"tag": language.PartOfSpeech.Tag(token.part_of_speech.tag).name,
"number": language.PartOfSpeech.Number(token.part_of_speech.number).name,
"mood": language.PartOfSpeech.Mood(token.part_of_speech.mood).name,
"person": language.PartOfSpeech.Person(token.part_of_speech.person).name,
"tense": language.PartOfSpeech.Tense(token.part_of_speech.tense).name
},
"dependencyEdge": {
"headTokenIndex": token.dependency_edge.head_token_index,
"label": language.DependencyEdge.Label(token.dependency_edge.label).name
},
"lemma": token.lemma
}
for token in analyze_result.tokens
]
my_analyze_result = {
"sentences": sentences,
"tokens": tokens,
"language": analyze_result.language,
"AnalyzeSyntaxResponse_to_str": str(analyze_result)
}
把資料送回去之前,會先進行 json 轉換,
然後再把它送回去:
analyze_result_json = json.dumps(my_analyze_result)
return analyze_result_json
以上就是我們在 Python 端所需要的程式碼。
最後別忘了用 git 記錄一下:
git add .
git commit -m "flask 提供語法分析服務"
git push -u origin master
明天我們再來看看外掛那邊,
如何發出請求、接受請求吧。


 iThome鐵人賽
iThome鐵人賽